Ayer participé en el segundo #MiércolesDeDatos, que replica el desafío semanal #TidyTuesday de su hermano anglófono por iniciativa de @R4DS_es, quienes colaboran para hacer accesible la biblia de la comunidad datera de R para la comunidad hispanoparlante.
El proyecto de ayer consitía en hacer un análisis de datos y visualización con información de los libros de Game of Thrones. Esto fue lo que compartí
Aproveché los datos de este #MiércolesDeDatos para probar una de las features que incluye ggforce (el acelerador de ggplot creado por Thomas Lin Pedersen).
Qué tipo de gráfico es éste?
El mismo Pedersen (cientista de datos en RStudio - @thomasp85 en Twitter) señala que hay una familia de estas figuras con nombres distintos. Y destaca cuales son para él las diferencias y particularidades de cada una de esas nomenclaturas (Sankey, Alluvial y Parrallel Sets).
En sus palabras (traducidas) sería algo así:
Hay un poco de confusión en la nomenclatura con esto. Insistiré en que los diagramas de Sankey son específicamente para flujos (y, a menudo, emplean una posición más suelta de los ejes) y los diagramas aluviales son para seguir los cambios temporales, pero todos podemos ser amigos, no importa cómo se llame.
Ya hace algún tiempo empecé a jugar con gráficos de este tipo. Se me ocurren rápido algunos ejemplos:
SANKEY
En primer lugar unos gráficos que fueron producidos con SankeyMatic (una recomendación de Crst_C).
(El ejercicio buscaba ilustrar el origen partidario de los votos de una alianza. El análisis completo acá).
ggalluvial
En segundo lugar intenté rehacer un gráfico hecho con SankeyMatic desde R, procurando reproducibilidad. Acá el original, abajo la versión reproducible:
El ejericio buscaba ilustrar como se distribuyeron las fuentes de finanicmiento privada de partidos políticos en la elección nacional de 2017 en la Provincia de Buenos Aires. El análisis completo acá.
Parrallel Sets
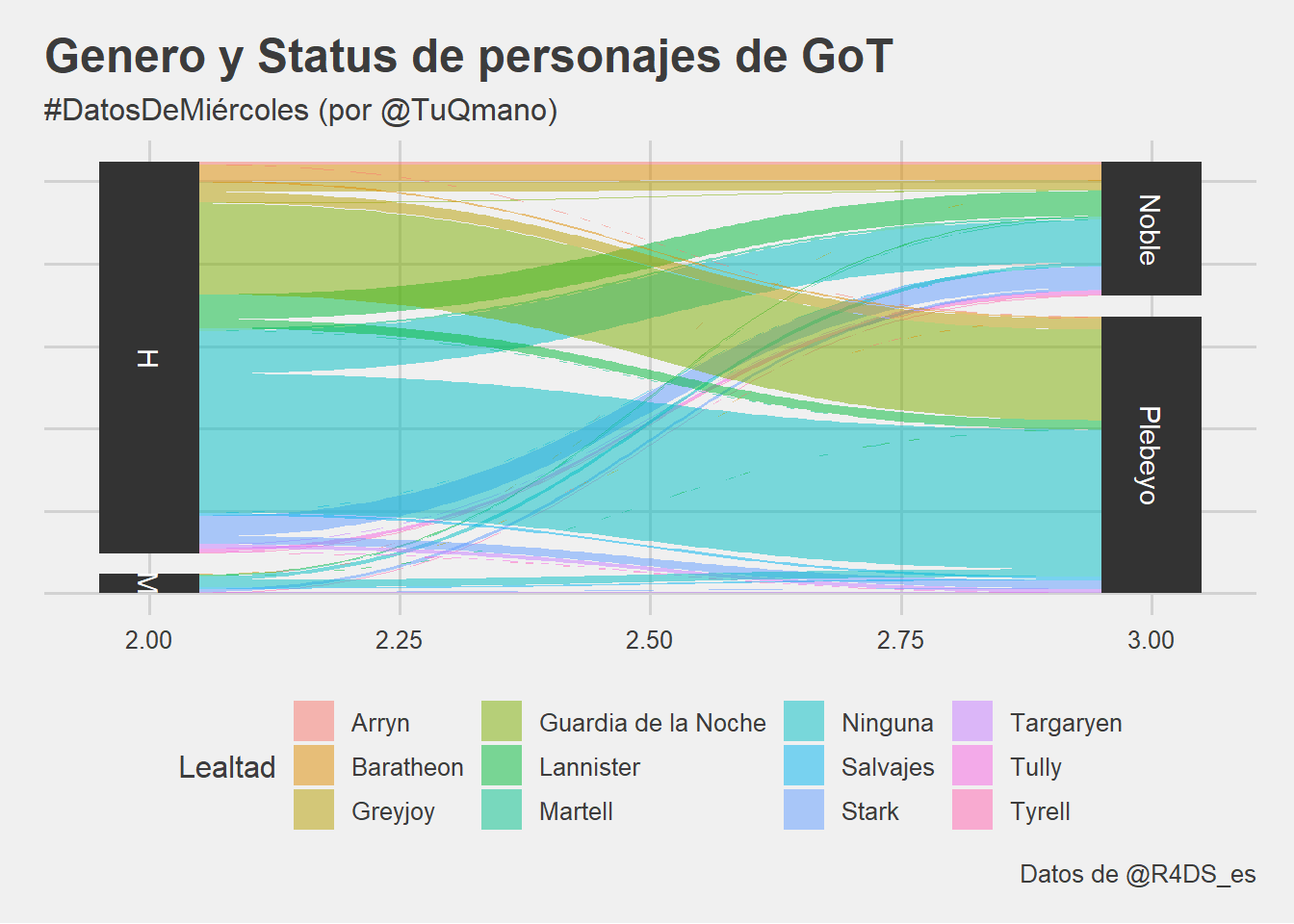
Ayer completé el trio con el ejemplo de GoT usando el geom_parrallel_sets de ggforce. Respecto de esta variante Pedersen agrega que:
El problema principal es que los datos para los gráficos de conjuntos paralelos generalmente no se representan muy bien en el formato tidy esperado por ggplot2, por lo que ggforce proporciona una función para obtener con ese formato.
Esta función amiga es gather_set_data(a:b), la cual selecciona las variables que queremos incluir en nuestros ejes. Genera nuevas variables llamadas id, x, y. Junto con value - el conteo de personajes por cada uno de los grupos que definimos- y Lealtad, que es la variable que usamos para definir los colores de las casas de GoT, tenemos toda la información.
El código completo y el plot son los siguiente:
library(tidyverse)library(ggforce)library(ggthemes)#GoT PLOT - #MiércolesDeDatosreadr::read_csv("https://raw.githubusercontent.com/cienciadedatos/datos-de-miercoles/master/datos/2019/2019-04-17/personajes_libro.csv") %>%#CARGAMOS DATA SETselect(2:4) %>%# SELECCIONAMOS COLUMNAS CON DATOS QUE VAMOS A USARgroup_by(lealtad, genero, noble) %>%# AGRUPAMOS POR TRES VARIABLESmutate(value =n()) %>%# CONTAMOS CUANTOS PERSONAJES HAY POR GRUPOungroup() %>%mutate(noble =ifelse(noble ==1, "Noble", "Plebeyo"), genero =ifelse(genero =="masculino", "H", "M")) %>%rename('Genero'='genero', 'Status'='noble', 'Lealtad'='lealtad') %>%gather_set_data(2:3) %>%# TRANSFORMACION TIDY DE PARRALLEL SETS (ggforce)ggplot(aes(x, id = id, split = y, value = value)) +# INICIA GRAFICOgeom_parallel_sets(aes(fill = Lealtad), alpha =0.5, axis.width =0.1) +geom_parallel_sets_axes(axis.width =0.1) +geom_parallel_sets_labels(colour ='white') +theme_fivethirtyeight() +theme(axis.text.y =element_blank()) +labs(title ="Genero y Status de personajes de GoT", subtitle ="#DatosDeMiércoles (por @TuQmano)", caption ="Datos de @R4DS_es")