argendata: un año
En este, nuestro primer cumpleañitos, quiero compartir un poco más de detalle del laburo datero que hay por detrás de este pequeño gran orgullo TuQmano. Y extender un agradecimiento por el enorme esfuerzo a todo fundar, pero en particular a “los datasets”, el equipo que lideró el trabajo que acá comparto y a nuestra capitana Pau Isaak.





🧱 Diseñar para durar: los fundamentos técnicos de Argendata
¿Qué es Argendata?
Argendata es una iniciativa de fundar que busca organizar, armonizar y publicar datos sobre Argentina con una lógica clara: que sirvan para entender mejor, discutir mejor y decidir mejor. En definitiva, un pequeño aporte que tiene una enorme ambición: transformar la Argentina.
Pero no se trata solo de subir textos y gráficos. Detrás del sitio hay una estructura técnica que permite mantener los datos vivos, trazables, disponibles y reproducibles. Una arquitectura pensada para que el contenido sea más que información: que sea evidencia y de la buena, confiable!
Los Datos: El Corazón de Argendata
TL;DR
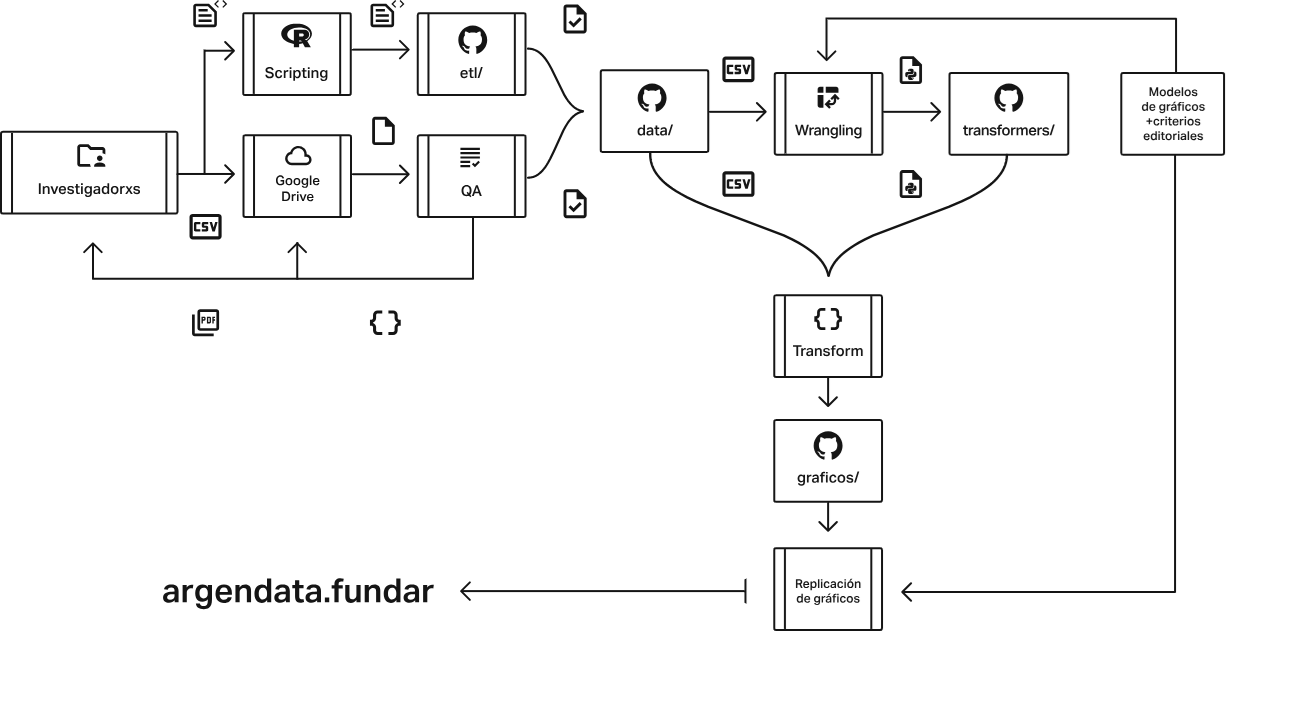
En Argendata, la calidad, transparencia y reproducibilidad de los datos son fundamentales para nutrir el debate público con información confiable. Nuestros procesos están diseñados para procurar que cada dato sea robusto y accesible. Nos basamos en tres pilares esenciales: la administración de recursos, que asegura la coherencia y armonización de los datos; un riguroso control de calidad y reportes; y la armonización del código fuente, clave para la reproducibilidad y actualización constante. Este enfoque nos permite transformar los datos generados por investigadores en las visualizaciones claras y útiles que encontrás en nuestro sitio.
Nuestras herramientas clave en el desarrollo de datos
Para lograr todo esto, en Argendata utilizamos un conjunto de herramientas y repositorios especializados. Cada uno cumple un rol crucial en el ciclo de vida de nuestros datos, desde la recolección y procesamiento hasta la visualización final. A continuación, un resumen de estas herramientas:
qa: Este repositorio (https://github.com/argendatafundar/qa) estructura y simplifica los procesos de creación y ejecución de controles de calidad sobre los conjuntos de datos. Facilita la administración del sistema de archivos y la interacción para el Control de Calidad (QA) entre investigadores y el equipo de datos.geonomencladores: Contiene un diccionario de entidades geográficas normalizado (https://github.com/argendatafundar/geonomencladores) esencial para la consistencia en el uso de datos geográficos.etl: Este proyecto (https://github.com/argendatafundar/etl) se centra en la armonización del proceso de Exploración, Transformación y Carga (ETL) de datos. Su objetivo es reducir la fricción en la actualización, automatizando pasos como la descarga de fuentes, la limpieza y la generación de datasets para visualizaciones.argendataR: Un paquete deR(https://github.com/argendatafundar/argendataR) que ofrece funciones auxiliares para el proceso ETL, optimizando el flujo de trabajo con fuentes y resultados.data: Aquí se comparten los datasets definitivos (https://github.com/argendatafundar/data), agrupados por tópicos y disponibles para descarga directa desde el sitio web de Argendata.data-transformers: Una biblioteca paraPython(https://github.com/argendatafundar/data-transformers) diseñada para facilitar la escritura, ejecución, reproducibilidad y versionado del código fuente que manipula datos estructurados. Su rol principal es formatear los datos para las visualizaciones del Frontend.transformers: Este repositorio (https://github.com/argendatafundar/transformers) aloja los scripts dePythonque actúan como “recetas” para transformar los datos dedataal formato requerido por el Frontend para la visualización.
Sobre nuestros datos
Un Vistazo (Más) de Cerca a Nuestras Herramientas
qa
El repositorio qa (https://github.com/argendatafundar/qa) es nuestro caballito de batalla para trabajar por la calidad y consistencia de los datos. Tiene dos funciones principales que resultan clave:
Organización y Administración:
qaestablece una estructura clara y estandarizada para el sistema de archivos compartido. Esto es crucial para que todos los investigadores y el equipo de datos trabajen con la misma lógica al guardar y buscar la información, minimizando así errores y datos duplicados. Asegura que los datos se almacenen de manera predecible, facilitando su gestión a largo plazo.Control de Calidad Interactivo: facilita una colaboración constante y efectiva entre los investigadores, que son quienes generan los datos, y nuestro equipo especializado. A través de este programa, se realizan validaciones sistemáticas que permiten detectar inconsistencias, anomalías o errores en etapas tempranas. Por ejemplo,
qapuede verificar que un campo numérico no contenga texto, que los rangos de fechas sean lógicos, o que los valores de una variable categórica se ajusten a un listado predefinido. Al automatizar estos controles,qaacelera el ciclo de desarrollo, reduce la carga de trabajo manual y garantiza que solo los datos más confiables y limpios avancen hacia las siguientes etapas de armonización y visualización. Es, en esencia, nuestro guardián de la integridad de los datos.
geonomencladores
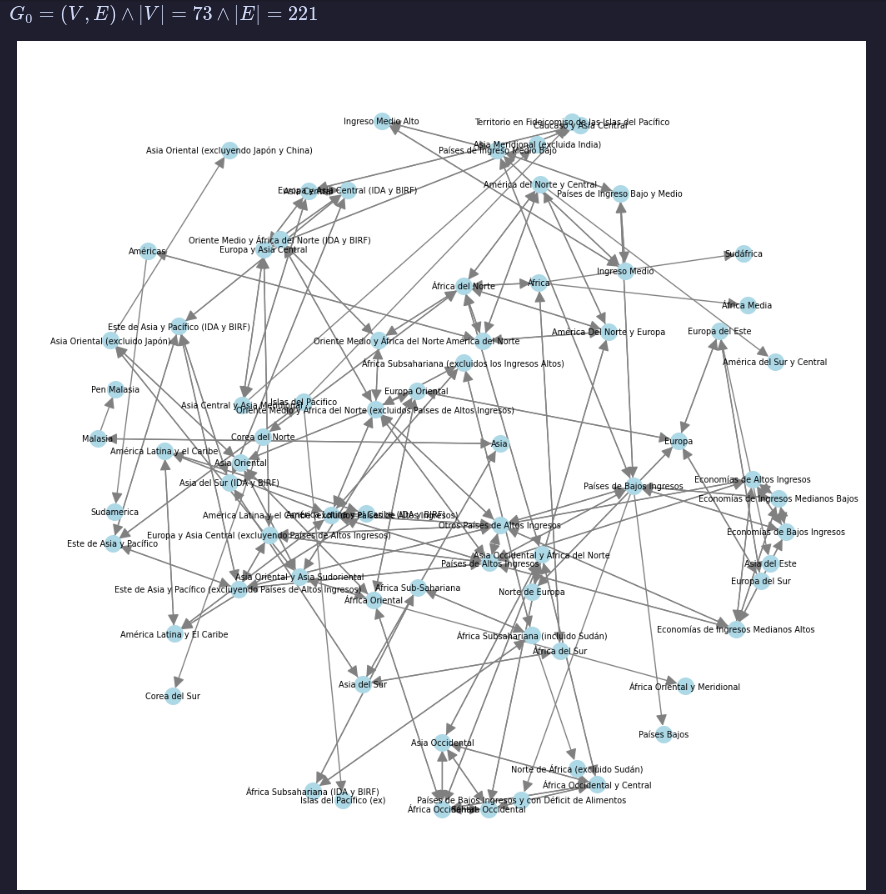
El geonomenclador es un componente esencial en Argendata. Este funciona como un diccionario estandarizado de entidades geográficas (países y regiones). Su propósito principal es armonizar datos provenientes de distintas fuentes, procurando asegurar que todos se refieran a las mismas ubicaciones de manera consistente.

Para construir esta herramienta vital, realizamos un exhaustivo trabajo de normalización de la nomenclatura de países. Esto implicó comparar los códigos estandarizados de diversas bases de datos. La priorización de estos códigos se basó en la proporción de uso de cada base sobre los datasets de nuestro proyecto, garantizando que el nomenclador refleje las realidades de nuestros datos.
Posteriormente, aplicamos técnicas de fuzzy matching para unificar los nombres de distintos países y regiones. Este proceso fue importante para resolver variaciones en la escritura o denominación de una misma entidad geográfica, como se ilustra en el siguiente gráfico, donde cada flecha representa la similitud entre dos regiones basada en sus nombres.
etl
El repositorio etl (https://github.com/argendatafundar/etl) es el motor que impulsa la generación y transformación de nuestros datos de forma programática y reproducible. Contiene los scripts en R que garantizan un proceso sistemático de Extracción, Transformación y Carga (ETL).
Este repositorio asegura la armonización del flujo de trabajo, lo que reduce la fricción en cada actualización de datos. Desde la descarga de fuentes raw hasta la limpieza y preparación de los datasets finales para las visualizaciones, etl automatiza pasos cruciales para mantener la coherencia y la eficiencia.
Un aspecto clave de etl es su enfoque en la reproducibilidad. Todos los scripts están diseñados para ser modulares y parametrizables, facilitando la colaboración entre investigadores y la actualización consistente de la información. Por ejemplo, promovemos el uso de código que se adapte automáticamente a cambios en los nombres de columnas a lo largo del tiempo, asegurando que los scripts sigan funcionando con nuevas versiones de las fuentes.
Los resultados finales de estos procesos de etl se almacenan directamente en el repositorio data/, listos para alimentar las visualizaciones en Argendata.
argendataR
El paquete argendataR (https://github.com/argendatafundar/argendataR) es una colección de funciones en R diseñada para simplificar y estandarizar el flujo de trabajo con las fuentes de datos y los outputs generados en el proceso de armonización (ETL). Este paquete es una herramienta indispensable para investigadores y el equipo de datos, ya que agiliza tareas repetitivas y asegura la consistencia en el manejo de la información.
Por ejemplo, una de sus funcionalidades centrales es la gestión de fuentes de datos, dividida en funciones para fuentes raw (originales) y clean (procesadas). Permite registrar y actualizar metadatos de las fuentes en Google Sheets, así como cargar y descargar archivos de Google Drive. Por ejemplo, con agregar_fuente_raw() y actualizar_fuente_raw(), los investigadores pueden gestionar las versiones de los datos brutos, mientras que agregar_fuente_clean() y actualizar_fuente_clean() se encargan de las versiones ya limpias y preparadas, asegurando que cumplan con los estándares de Argendata (ej., nombres de columnas consistentes, formato long).
R
# Ejemplo de cómo se registra una nueva fuente raw por primera vez
library(argendataR)
## basic example code
agregar_fuente_raw(url = "https://www.ejemplo.com",
nombre = "Ejemplo",
institucion = "Ejemplo",
actualizable = TRUE,
fecha_descarga = "2021-01-01",
fecha_actualizar = "2022-01-01",
path_raw = "ejemplo.csv",
script = "ejemplo.R")Además, argendataR es clave en la generación de los outputs finales. Su función principal, write_output(), es crucial para generar los archivos .json con datos y metadatos que Argendata necesita para sus visualizaciones. Opcionalmente, también puede exportar un .csv siguiendo los estándares de Fundar (UTF-8, delimitadores específicos), lo que garantiza la compatibilidad y facilidad de uso de nuestros datasets. Esta función encapsula toda la complejidad del formato de salida, permitiendo a los investigadores centrarse en el procesamiento de los datos.
R
# Ejemplo simplificado de uso de write_output para un dataset # df_output sería el data frame ya procesado y listo
write_output( data = df_output,
extension = 'csv',
output_name = 'A1_inb_pib',
subtopico = 'ACECON',
fuentes = 'World Development Indicators',
analista = 'Andrés Salles',
aclaraciones = NULL,
exportar = TRUE,
pk = c("anio", "iso3"),
es_serie_tiempo = TRUE,
columna_indice_tiempo = "anio",
columna_geo_referencia = "iso3",
nivel_agregacion = "pais",
nullables = FALSE,
etiquetas_indicadores = list("diferencia_inb_pbi" = "Diferencia entre Ingreso Bruto Nacional y PBI"),
unidades = "Porcentaje respecto al PBI",
classes = NULL)En resumen, argendataR es la caja de herramientas para el flujo de trabajo de datos en Argendata, promoviendo la sistematización, la calidad y la eficiencia en la producción de conocimiento. Las salidas finales de estos procesos son las que se comparten y actualizan en el repositorio data y alimentan el sitio argendata.fund.ar para la descarga de datos.
data
El repositorio data (https://github.com/argendatafundar/data) es el punto central de almacenamiento y distribución de los datasets finales que se publican en Argendata. Estos conjuntos de datos son el resultado del proceso semi-automatizado de reproducibilidad (ETL), lo que asegura su consistencia y calidad. Básicamente, data es la vidriera donde se consolidan y comparten los datos producidos por los investigadores, listos para su uso y descarga.
Organización de los datos
Para mantener la claridad y facilitar el acceso, los datos en este repositorio están meticulosamente organizados:
Codificación por Tópico: Cada tópico de Argendata tiene un código único de seis letras en mayúsculas (ej.,
CAMCLIpara “Cambio Climático”,PRECIOpara “Inflación”). Estos códigos sirven como identificadores únicos y estructuran el sistema de archivos del repositorio, agrupando los datasets por su tema principal.Archivos por Dataset: Dentro de la carpeta de cada tópico, se encuentran dos tipos de archivos para cada dataset individual:
El dataset original limpio en formato
.csv. Estos son los datos ya procesados y listos para ser utilizados.Los metadatos en formato
.json, que acompañan a cada dataset con el mismo nombre. Estos archivos.jsonson cruciales porque proveen información detallada sobre el dataset, incluyendo sus fuentes (fuentes), tipo de extensión (extension), analistas responsables (analista), los tipos de datos por variable y otras especificaciones necesarias para su correcta interpretación y uso.
Por ejemplo, el dataset de inflación
PRECIO/12_tasa_de_inflacion_mensual_argentina_ene1989_dic1993viene acompañado de su.csvcon las columnasfechaeinflacion_mensual, y un.jsoncon sus metadatos (subtopico,output_name,extension,analista,fuentes). Este esquema garantiza que los usuarios no solo obtengan los datos, sino también el contexto y la información necesaria para entenderlos y utilizarlos correctamente.
Estructura del sistema de archivos
La organización del repositorio sigue un esquema lógico que refleja la clasificación por tópico:
├── TOPICO
├── ...
├── CAMCLI
│ ├── dataset.csv
│ ├── dataset.json
│ └── ...
└── COMEXT
├── cambio_destinos_exportacion.csv
├── cambio_destinos_exportacion.json
...Esta estructura jerárquica facilita la navegación y la identificación de los conjuntos de datos, permitiendo a los usuarios encontrar rápidamente la información de su interés.
Los datos almacenados en este repositorio son los que se disponibilizan directamente para la descarga de los usuarios desde el sitio web de Argendata. Además, son la base para el procesamiento posterior realizado por el repositorio transformers, que los adapta para la visualización interactiva en el Frontend de argendata.fund.ar.
data-transformers
El repositorio data-transformers (https://github.com/argendatafundar/data-transformers) es una biblioteca de Python diseñada para ser un componente clave en el análisis y procesamiento manual-asistido de datos estructurados dentro de Argendata. Su propósito principal es facilitar la escritura, ejecución, reproducibilidad y el versionado del código fuente que manipula estos datos.
Esta herramienta se enfoca en el formato y la preparación de los datos según las necesidades específicas del código utilizado por el Frontend para las visualizaciones. No se trata de la generación inicial de datos (eso ocurre en etl), sino de las transformaciones finales que optimizan los datasets para su presentación interactiva. Esto puede incluir tareas como:
Filtrado de valores: seleccionar subconjuntos de datos relevantes para una visualización particular.
Selección y renombramiento de variables: ajustar los nombres de las columnas o seleccionar solo aquellas que son necesarias para el gráfico final.
Agregaciones o pivotes específicos: reestructurar los datos para que se adapten a los requisitos del componente de visualización.
Al centralizar estas transformaciones en data-transformers, se garantiza que el paso final de preparación de datos sea consistente y que cualquier cambio necesario en el formato de visualización se aplique de manera eficiente y reproducible. Esto es vital para mantener la agilidad en el desarrollo de nuevas visualizaciones y la calidad de la información mostrada en el sitio.
transformers
El repositorio transformers (https://github.com/argendatafundar/transformers) contiene los scripts en Python que actúan como “recetas” ejecutables y autocontenidas. Básicamente, son programas diseñados para aplicar una serie de instrucciones de mutación a un dataset, transformándolo específicamente para su visualización en el sitio web de Argendata.
Estos scripts van un paso más allá de la armonización de datos que se realiza en el proceso etl. Su objetivo es una normalización más estricta, donde se deja únicamente la información imprescindible para que el gráfico se pueda visualizar. Así, se generan archivos mucho más livianos y optimizados para el Frontend.
Cada transformer se explica por sí mismo en su funcionalidad: describe lo que hace, lo que facilita mucho su comprensión y garantiza su fácil ejecución en un proceso automatizado. La relación con data-transformers es directa: data-transformers es la librería que provee las funciones base que estos scripts utilizan para construir sus “recetas”.
El trabajo en este repositorio se organiza por tópicos, reflejando la estructura de Argendata:
├── TOPICO
├── ...
├── AGROPE
│ ├── mappings.json
│ ├── TOPICO_gXX_transformer.py
│ └── ...
└── TRANEN
├── mappings.json
├── TRANEN_g01_transformer.py
├── TRANEN_g02_transformer.py
├── TRANEN_g03_transformer.py
├── TRANEN_g04_transformer.py
├── TRANEN_g05_transformer.py
├── TRANEN_g06_transformer.py
├── TRANEN_g07_transformer.py
├── TRANEN_g08_transformer.py
├── TRANEN_g09_transformer.py
├── TRANEN_g10_transformer.py
├── TRANEN_g11_transformer.py
├── TRANEN_g12_transformer.py
├── TRANEN_g13_transformer.py
├── TRANEN_g14_transformer.py
├── TRANEN_g15_transformer.py
├── TRANEN_g16_transformer.py
├── TRANEN_g17_transformer.py
├── TRANEN_g18_transformer.py
└── TRANEN_g19_transformer.pyCada dataset publicado en data (resultado del proceso ETL) tiene una correspondencia con uno o más transformers aquí. Un dataset de data (por ejemplo, matriz_prim_mundo_historic_larga.csv en data) es el “insumo” para un transformer (como TRANEN_g01_transformer.py en transformers. Esta equivalencia está documentada en un archivo mappings.json dentro de cada subdirectorio de tópico en este repositorio.
Un ejemplo de cómo opera un transformer es el TRANEN_g01_transformer.py, que toma un DataFrame y aplica una serie de transformaciones usando funciones de data-transformers (como query, rename_cols y sort_values) para preparar los datos para la visualización final. Esto asegura que los datos sean presentados de forma óptima y coherente en la web.
Python
# Extracto del código de TRANEN_g01_transformer.py
from pandas import DataFrame
from data_transformers import chain, transformer
# DEFINITIONS_START
@transformer.convert
def query(df: DataFrame, condition: str):
df = df.query(condition)
return df
@transformer.convert
def rename_cols(df: DataFrame, map):
df = df.rename(columns=map)
return df
@transformer.convert
def sort_values(df: DataFrame, how: str, by: list):
if how not in ['ascending', 'descending']:
raise ValueError('how must be either "ascending" or "descending"')
return df.sort_values(by=by, ascending=how == 'ascending')
# DEFINITIONS_END
# PIPELINE_START
pipeline = chain(
query(condition='tipo_energia != "Total"'),
rename_cols(map={'tipo_energia': 'indicador', 'valor_en_twh': 'valor'}),
sort_values(how='ascending', by=['anio', 'indicador'])
)
# PIPELINE_END
# start()
# RangeIndex: 836 entries, 0 to 835
# Data columns (total 4 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 anio 836 non-null int64
# 1 tipo_energia 836 non-null object
# 2 valor_en_twh 836 non-null float64
# 3 porcentaje 836 non-null float64
#
# | | anio | tipo_energia | valor_en_twh | porcentaje |
# |---:|-------:|:-----------------|---------------:|-------------:|
# | 0 | 1800 | Otras renovables | 0 | 0 |
#
# ------------------------------
#
# query(condition='tipo_energia != "Total"')
# Index: 760 entries, 0 to 759
# Data columns (total 4 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 anio 760 non-null int64
# 1 tipo_energia 760 non-null object
# 2 valor_en_twh 760 non-null float64
# 3 porcentaje 760 non-null float64
#
# | | anio | tipo_energia | valor_en_twh | porcentaje |
# |---:|-------:|:-----------------|---------------:|-------------:|
# | 0 | 1800 | Otras renovables | 0 | 0 |
#
# ------------------------------
#
# rename_cols(map={'tipo_energia': 'indicador', 'valor_en_twh': 'valor'})
# Index: 760 entries, 0 to 759
# Data columns (total 4 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 anio 760 non-null int64
# 1 indicador 760 non-null object
# 2 valor 760 non-null float64
# 3 porcentaje 760 non-null float64
#
# | | anio | indicador | valor | porcentaje |
# |---:|-------:|:-----------------|--------:|-------------:|
# | 0 | 1800 | Otras renovables | 0 | 0 |
#
# ------------------------------
#
# sort_values(how='ascending', by=['anio', 'indicador'])
# Index: 760 entries, 76 to 227
# Data columns (total 4 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 anio 760 non-null int64
# 1 indicador 760 non-null object
# 2 valor 760 non-null float64
# 3 porcentaje 760 non-null float64
#
# | | anio | indicador | valor | porcentaje |
# |---:|-------:|:----------------|--------:|-------------:|
# | 76 | 1800 | Biocombustibles | 0 | 0 |
#
# ------------------------------
# Este proceso en dos etapas (primero ETL, luego transformación para Frontend) asegura la calidad del dato base y al mismo tiempo la flexibilidad y eficiencia en la presentación visual de la información.
——–
Hasta acá un resumen de lo que fue el primer año, centrado en el camino de los datos. En próximas publicaciones, espero con blogueros inivtados, avanzaremos con más detalle sobre algunos de los procesos, con especial atención al trabajo dedicado a la visualización.
Hasta la próxima y feliz cumple a nosotros =)